


Technology
Training AI models might not need enormous data centres – Crypto News
Once, the world’s richest men competed over yachts, jets and private islands. Now, the size-measuring contest of choice is clusters. Just 18 months ago, OpenAI trained GPT-4, its then state-of-the-art large language model (LLM), on a network of around 25,000 then state-of-the-art graphics processing units (GPUs) made by Nvidia. Now Elon Musk and Mark Zuckerberg, bosses of X and Meta respectively, are waving their chips in the air: Mr Musk says he has 100,000 GPUs in one data centre and plans to buy 200,000. Mr Zuckerberg says he’ll get 350,000.
This contest to build ever-bigger computing clusters for ever-more-powerful artificial-intelligence (AI) models cannot continue indefinitely. Each extra chip adds not only processing power but also to the organisational burden of keeping the whole cluster synchronised. The more chips there are, the more time the data centre’s chips will spend shuttling data around rather than doing useful work. Simply increasing the number of GPUs will provide diminishing returns.
Computer scientists are therefore looking for cleverer, less resource-intensive ways to train future AI models. The solution could lie with ditching the enormous bespoke computing clusters (and their associated upfront costs) altogether and, instead, distributing the task of training between many smaller data centres. This, say some experts, could be the first step towards an even more ambitious goal—training AI models without the need for any dedicated hardware at all.
Training a modern AI system involves ingesting data—sentences, say, or the structure of a protein—that has had some sections hidden. The model makes a guess at what the hidden sections might contain. If it makes the wrong guess, the model is tweaked by a mathematical process called backpropagation so that, the next time it tries the same prediction, it will be infinitesimally closer to the correct answer.
I knew you were trouble
The problems come when you want to be able to work “in parallel”—to have two, or 200,000, GPUs working on backpropagation at the same time. After each step, the chips share data about the changes they have made. If they didn’t, you wouldn’t have a single training run, you’d have 200,000 chips training 200,000 models on their own. That data-sharing process starts with “checkpointing”, in which a snapshot of the training so far is created. This can get complicated fast. There is only one link between two chips, but 190 between 20 chips and almost 20bn for 200,000 chips. The time it takes to checkpoint and share data grows commensurately. For big training runs, around half the time can often be spent on these non-training steps.
All that wasted time gave Arthur Douillard, an engineer at Google DeepMind, an idea. Why not just do fewer checkpoints? In late 2023, he and his colleagues published a method for “Distributed Low-Communication Training of Language Models”, or DiLoCo. Rather than training on 100,000 GPUs, all of which speak to each other at every step, DiLoCo describes how to distribute training across different “islands”, each still a sizeable data centre. Within the islands, checkpointing continues as normal, but across them, the communication burden drops 500-fold.
There are trade-offs. Models trained this way seem to struggle to hit the same peak performance as those trained in monolithic data centres. But interestingly, that impact seems to exist only when the models are rated on the same tasks they are trained on: predicting the missing data.
When they are turned to predictions that they’ve never been asked to make before, they seem to generalise better. Ask them to answer a reasoning question in a form not in the training data, and pound for pound they may outclass the traditionally trained models. That could be an artefact of each island of compute being slightly freer to spiral off in its own direction between checkpointing runs, when they get hauled back on task. Like a cohort of studious undergraduates forming their own research groups rather than being lectured to en masse, the end result is therefore slightly less focused on the task at hand, but with a much wider experience.
Vincent Weisser, founder of Prime Intellect, an open-source AI lab, has taken DiLoCo and run with it. In November 2024 his team completed training on Intellect-1, a 10bn-parameter LLM comparable to Meta’s centrally trained Llama 2, which was state-of-the-art when released in 2023.
Mr Weisser’s team built OpenDiLoCo, a lightly modified version of Mr Douillard’s original, and set it to work training a new model using 30 GPU clusters in eight cities across three continents. In his trials, the GPUs ended up actively working for 83% of the time—that’s compared with 100% in the baseline scenario, in which all the GPUs were in the same building. When training was limited to data centres in America, they were actively working for 96% of the time. Instead of checkpointing every training step, Mr Weisser’s approach checkpoints only every 500 steps. And instead of sharing all the information about every change, it “quantises” the changes, dropping the least significant three-quarters of the data.
For the most advanced labs, with monolithic data centres already built, there is no pressing reason to make the switch to distributed training yet. But, given time, Mr Douillard thinks that his approach will become the norm. The advantages are clear, and the downsides—at least, those illustrated by the small training runs that have been completed so far—seem to be fairly limited.
For an open-source lab like Prime Intellect, the distributed approach has other benefits. Data centres big enough to train a 10bn-parameter model are few and far between. That scarcity drives up prices to access their compute—if it is even available on the open market at all, rather than hoarded by the companies that have built them. Smaller clusters are readily available, however. Each of the 30 clusters Prime Intellect used was a rack of just eight GPUs, with up to 14 of the clusters online at any given time. This resource is a thousand times smaller than data centres used by frontier labs, but neither Mr Weisser nor Mr Douillard see any reason why their approach would not scale.
For Mr Weisser, the motivation for distributing training is also to distribute power—and not just in the electrical sense. “It’s extremely important that it’s not in the hands of one nation, one corporation,” he says. The approach is hardly a free-for-all, though—one of the eight-GPU clusters he used in his training run costs $600,000; the total network deployed by Prime Intellect would cost $18m to buy. But his work is a sign, at least, that training capable AI models does not have to cost billions of dollars.
And what if the costs could drop further still? The dream for developers pursuing truly decentralised AI is to drop the need for purpose-built training chips entirely. Measured in teraflops, a count of how many operations a chip can do in a second, one of Nvidia’s most capable chips is roughly as powerful as 300 or so top-end iPhones. But there are a lot more iPhones in the world than GPUs. What if they (and other consumer computers) could all be put to work, churning through training runs while their owners sleep?
The trade-offs would be enormous. The ease of working with high-performance chips is that, even when distributed around the world, they are at least the same model operating at the same speed. That would be lost. Worse, not only would the training progress need to be aggregated and redistributed at each checkpoint step, so would the training data itself, since typical consumer hardware is unable to store the terabytes of data that goes into a cutting-edge LLM. New computing breakthroughs would be required, says Nic Lane of Flower, one of the labs trying to make that approach a reality.
The gains, though, could add up, with the approach leading to better models, reckons Mr Lane. In the same way that distributed training makes models better at generalising, models trained on “sharded” datasets, where only portions of the training data are given to each GPU, could perform better when confronted with unexpected input in the real world. All that would leave the billionaires needing something else to compete over.
© 2025, The Economist Newspaper Limited. All rights reserved. From The Economist, published under licence. The original content can be found on www.economist.com
Catch all the Technology News and Updates on Live Mint. Download The Mint News App to get Daily Market Updates & Live Business News.
MoreLess














-
others1 week ago
JPY soft and underperforming G10 in quiet trade – Scotiabank – Crypto News
-

 Blockchain1 week ago
Blockchain1 week agoXRP Price Gains Traction — Buyers Pile In Ahead Of Key Technical Breakout – Crypto News
-

 Technology7 days ago
Technology7 days agoSam Altman says OpenAI is developing a ‘legitimate AI researcher’ by 2028 that can discover new science on its own – Crypto News
-

 De-fi1 week ago
De-fi1 week agoNearly Half of US Retail Crypto Holders Haven’t Earned Yield: MoreMarkets – Crypto News
-

 De-fi6 days ago
De-fi6 days agoBittensor Rallies Ahead of First TAO Halving – Crypto News
-

 Technology1 week ago
Technology1 week agoMicrosoft ‘tricked users into pricier AI-linked 365 plans,’ says Australian watchdog; files lawsuit – Crypto News
-
others1 week ago
GBP/USD holds steady after UK data, US inflation fuels rate cut bets – Crypto News
-

 De-fi1 week ago
De-fi1 week agoAI Sector Rebounds as Agent Payment Systems Gain Traction – Crypto News
-

 Blockchain1 week ago
Blockchain1 week agoBig Iran Bank Goes Bankrupt, Affecting 42 Million Customers – Crypto News
-
Business1 week ago
Crypto Market Rally: BTC, ETH, SOL, DOGE Jump 3-7% as US China Trade Talks Progress – Crypto News
-

 Cryptocurrency1 week ago
Cryptocurrency1 week agoCrypto wrap: Bitcoin, Ethereum, BNB, Solana, and XRP muted after CPI report – Crypto News
-

 Cryptocurrency1 week ago
Cryptocurrency1 week agoBitcoin Accumulation Patterns Show Late-Stage Cycle Maturity, Not Definite End: CryptoQuant – Crypto News
-
Technology1 week ago
Ethereum Supercycle Strengthens as SharpLink Gaming Withdraws $78.3M in ETH – Crypto News
-

 Blockchain1 week ago
Blockchain1 week agoIBM Set to Launch Platform for Managing Digital Assets – Crypto News
-
 others1 week ago
others1 week agoGBP/USD floats around 1.3320 as softer US CPI reinforces Fed cut bets – Crypto News
-

 Blockchain1 week ago
Blockchain1 week agoEthereum Rebounds From Bull Market Support: Can It Conquer The ‘Golden Pocket’ Next? – Crypto News
-

 Cryptocurrency1 week ago
Cryptocurrency1 week agoWestern Union eyes stablecoin rails in pursuit of a ‘super app’ vision – Crypto News
-
De-fi1 week ago
Nearly Half of US Retail Crypto Holders Haven’t Earned Yield: MoreMarkets – Crypto News
-
others1 week ago
Indian Court Declares XRP as Property in WazirX Hack Case – Crypto News
-
 Blockchain1 week ago
Blockchain1 week agoSolana Eyes $210 Before Its Next Major Move—Uptrend Or Fakeout Ahead? – Crypto News
-

 De-fi1 week ago
De-fi1 week agoHYPE Jumps 10% as Robinhood Announces Spot Listing – Crypto News
-
others1 week ago
Platinum price recovers from setback – Commerzbank – Crypto News
-

 De-fi1 week ago
De-fi1 week agoREP Jumps 50% in a Week as Dev Gets Community Support for Augur Fork – Crypto News
-

 Technology1 week ago
Technology1 week agoMint Explainer | India’s draft AI rules and how they could affect creators, social media platforms – Crypto News
-
 Technology1 week ago
Technology1 week agoBenQ MA270U review: A 4K monitor that actually gets MacBook users right – Crypto News
-

 De-fi6 days ago
De-fi6 days agoBitcoin Dips Under $110,000 After Fed Cuts Rates – Crypto News
-

 Blockchain1 week ago
Blockchain1 week agoEntire Startup Lifecycle to Move Onchain – Crypto News
-
De-fi1 week ago
Nearly Half of US Retail Crypto Holders Haven’t Earned Yield: MoreMarkets – Crypto News
-

 Blockchain1 week ago
Blockchain1 week agoXRP/BTC Retests 6-Year Breakout Trendline, Analyst Calls For Decoupling – Crypto News
-

 Cryptocurrency1 week ago
Cryptocurrency1 week agoUSDJPY Forecast: The Dollar’s Winning Streak Why New Highs Could Be At Hand – Crypto News
-
others1 week ago
Is Changpeng “CZ” Zhao Returning To Binance? Probably Not – Crypto News
-

 De-fi1 week ago
De-fi1 week agoTokenized Nasdaq Futures Enter Top 10 by Volume on Hyperliquid – Crypto News
-

 Cryptocurrency1 week ago
Cryptocurrency1 week agoNEAR’s inflation reduction vote fails pass threshold, but it may still be implemented – Crypto News
-

 Technology1 week ago
Technology1 week agoSurvival instinct? New study says some leading AI models won’t let themselves be shut down – Crypto News
-

 De-fi1 week ago
De-fi1 week agoMetaMask Fuels Airdrop Buzz With Token Claim Domain Registration – Crypto News
-
Business1 week ago
Crypto ETFs Attract $1B in Fresh Capital Ahead of Expected Fed Rate Cut This Week – Crypto News
-

 Cryptocurrency1 week ago
Cryptocurrency1 week agoGold Price Forecast 2025, 2030, 2040 & Investment Outlook – Crypto News
-

 Cryptocurrency1 week ago
Cryptocurrency1 week agoCitigroup and Coinbase partner to expand digital-asset payment capabilities – Crypto News
-

 Cryptocurrency1 week ago
Cryptocurrency1 week agoInside Bitwise’s milestone solana ETF launch – Crypto News
-

 Cryptocurrency7 days ago
Cryptocurrency7 days agoWhy Is Pi Network’s (PI) Price Up by Double Digits Today? – Crypto News
-
others7 days ago
Can ASTER Price Rebound 50% as Whale Activity and Bullish Pattern Align? – Crypto News
-
 others1 week ago
others1 week agoGold weakens as US-China trade optimism lifts risk sentiment, focus turns to Fed – Crypto News
-
 De-fi1 week ago
De-fi1 week agoCRO Jumps After Trump’s Truth Social Announces Prediction Market Partnership with Crypto.Com – Crypto News
-

 Cryptocurrency1 week ago
Cryptocurrency1 week agoKERNEL price goes vertical on Upbit listing, hits $0.23 – Crypto News
-
Technology1 week ago
Breaking: $2.6B Western Union Announces Plans for Solana-Powered Stablecoin by 2026 – Crypto News
-

 Blockchain7 days ago
Blockchain7 days agoVisa To Support Four Stablecoins on Four Blockchains – Crypto News
-
 De-fi7 days ago
De-fi7 days agoCrypto Market Edges Lower While US Stocks Hit New Highs – Crypto News
-
 others7 days ago
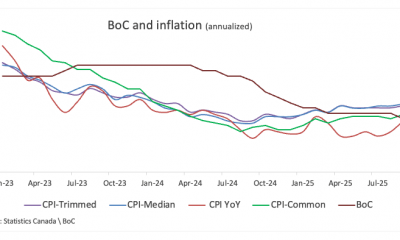
others7 days agoBank of Canada set to cut interest rate for second consecutive meeting – Crypto News
-

 Technology6 days ago
Technology6 days agoGiving Nvidias Blackwell chip to China would slash USs AI advantage, experts say – Crypto News
-

 Business6 days ago
Business6 days agoStarbucks Says Turnaround Strategy Drives Growth in Global Sales – Crypto News